
Welcome to the Brains Blog’s new Symposium series on the Cognitive Science of Philosophy! The aim of the series is to examine the use of methods from the cognitive sciences to generate philosophical insight. Each symposium is comprised of two parts. In the target post, a practitioner describes their use of the method under discussion and explains why they find it philosophically fruitful. A commentator then responds to the target post and discusses the strengths and limitations of the method. In this inaugural symposium, Joe Ulatowski, Dan Weijers, and Justin Systma discuss how corpus methods can be philosophically useful, with Colin Allen providing commentary.
* * * * * * * * * * * *
Corpus Methods in Philosophy
Joe Ulatowski, Dan Weijers, and Justin Sytsma
_________
Philosophers commonly make claims about words or the concepts they are taken to express. Often the focus is on “ordinary” words (or concepts), although philosophers have also been concerned with technical terms. Sometimes engagement with concepts is the purpose of the research, as when a philosopher offers a conceptual analysis. Sometimes it serves as background, with philosophers laying out a concept in order to argue that it should be revised. And sometimes it is more instrumental, with conceptual issues arising while philosophers pursue non-conceptual questions.
Given this, it is (perhaps) surprising and (decidedly) unfortunate that philosophers do not generally employ tools designed for the systematic observation of the use of words. This is slowly beginning to change, however, with philosophers increasingly making use of corpus methods. While we cannot hope to detail the range of corpora or corpus methods that have been employed by philosophers, let alone the range that could be employed, in this short post we will offer a brief overview of corpus methods in philosophy, focusing on our own work. Interested readers can find a range of examples in the video presentations recorded as part of the recent Corpus Fortnight event and in a number of overviews focused on philosophical use of corpus methods (Bluhm 2016, Mejía-Ramos et al. 2019, Sytsma et al. 2019, Caton 2020).
As experimental philosophers, each of us has begun to integrate corpus methods into our own research, whether simply to get a “feel” for the use of a term or to more carefully test linguistic hypotheses. One advantage of corpus methods for experimental philosophy is that they can offer a further way to test our hypotheses, one free of some encumbrances common in more standard experimental contexts, even as it inevitably introduces others. While this is far from the only benefit philosophers can (and have) derived from the use of corpus methods, it is the one that we focus on here.
I.
Corpus linguistics is a sub-discipline of linguistics that aims to collect and analyse existing, “real world” linguistic data (Biber et al. 1998, McCarthy and O’Keefe 2010, McEnery and Wilson 2001). Corpus analysis involves corpora: collections of written or oral texts. Corpora are typically curated, aiming to give a balanced and representative picture of the target domain of language use. The domain might be relatively general or highly specific, focusing on only certain types of texts or utterances (e.g., articles from specific disciplines, texts from certain time periods, the utterances of children). In addition, corpora often include further information, such as the base form of the words, part of speech, or syntactic structure, as well as various types of metadata, such as the source of the text or the age of the person making the utterance.
Advances in computing and the advent of the internet have enabled corpora to grow in size and number and to be made freely accessible around the world. One of the most commonly employed English-language corpora among philosophers is the Corpus of Contemporary American English (COCA), which is comprised of over 1 billion words. COCA, along with a number of other corpora, is available here. Sophisticated search tools have been developed for such corpora, allowing users to easily determine how often a word, lemma, or phrase occurs in the corpus, the contexts in which it occurs, and more.
A couple of brief illustrations are in order. In a recent paper, one of us ran a number of studies looking at a range of attributions, including responsibility attributions, and performed a few simple searches using the non-academic portions of COCA as background (Sytsma ms). For instance, while Talbert (2019, 2) asserts that “in everyday speech, one often hears references to people’s ‘moral responsibility’,” Sytsma found that the use of “moral responsibility” is in fact rather uncommon (69 occurrences compared to 9,501 for “responsibility”). In a related paper, Sytsma et al. (2019) used COCA to look at collocates for the phrases “responsible for the” and “caused the.” They used the search features to determine which nouns most frequently occurred after each of these phrases, finding that they have a decidedly negative tinge (e.g., “death,” “accident,” “crash”), as confirmed by independent raters. In addition to giving occurrence counts for simple or sophisticated searches, COCA also provides the context for those occurrences. Fischer and Sytsma (ms) have made use of this in a recent paper, using COCA to create a random sample of 500 sentences with the word “zombie” in it, which was then used to assess the relative occurrence frequency of different senses of this term.
Other tools go further than mere searches. For instance, philosophers have employed topic-modelling algorithms to extract abstract topics for a collection of documents (see, e.g., Allen and Murdock (forthcoming) for discussion with regard to history and philosophy of science and Weatherson (2020) for application to philosophy journals). Other work has used distributional semantic models that map terms onto a geometric space based on the context in which they occur across the corpus and such that the distance between the term offers a measure of similarity of meaning. Continuing with the previous example, Sytsma et al. (2019) used the LSAfun package in R (Günther et al. 2015) to query a large premade semantic space (EN_100k_lsa), finding that “cause” and “responsible” were relatively close together and, in line with the previous findings, that they tended to be close to terms with a clear negative connotation, such as “blame” and “fault.” Semantic models can also be used to investigate how word meaning has changed over time. For example, Ulatowski (ms) uses the Macroscope (Li et al. 2019) to look at the meaning of “truth” diachronically.
The full text for many corpora is also available, including COCA, allowing one to build one’s own semantic spaces for specific purposes. For example, Sytsma et al. built a semantic space using the non-academic portions of COCA with the phrases “caused the” and “responsible for the” treated as individual terms. They found that they were extremely close together in the resulting space, suggesting that they have similar meanings as captured by the contexts in which they are used in the corpus.
In addition to the large number of both general and specialty corpora available online, the internet can be used both as a corpus and for building corpora. While there is disagreement about how suitable the internet is for use as a corpus, standard web searches can provide at least some evidence for linguistic hypotheses, especially in conjunction with other corpora (for a few philosophical examples, see Knobe and Prinz 2008, Reuter 2011, Sytsma and Reuter 2017). The use of the internet for building a corpus, by contrast, is relatively uncontroversial. And a number of philosophers have used the web to create specialty corpora, such as compiling texts from Philosophy of Science (Malaterre et al. 2019), the works read by Darwin (Murdock et al. 2017), the works of Nietzsche (Alfano and Cheong 2019), and the two main online encyclopaedias of philosophy (Sytsma et al. 2019), among others. To give but one more example, a number of researchers have used JSTOR’s Data for Research to perform various searches on academic journals. For instance, Andow (2015) compares intuition-talk between philosophy and non-philosophy journals and Mizrahi (forthcoming) looks at the use of “truth,” “knowledge,” and “understanding” to explore how scientific practitioners conceive of scientific progress.
II.
Why should philosophers use corpora? As noted above, corpora can provide philosophers with examples of the use of words “in the wild.” Insofar as philosophers put forward hypotheses or make assertions that either concern or generate predictions about word use among some population, the claims can be empirically tested. And corpus methods provide one valuable way of doing so.
Not surprisingly, as experimental philosophers we firmly believe that empirical claims call for empirical support. While we adopt a broad conception of experimental philosophy (Sytsma and Livengood 2016, Sytsma 2017), much of the work that has been done concerns “intuitions” and tests linguistic or conceptual claims. Most frequently this has involved the use of questionnaires, often with participants reading a short case description that mirrors “traditional” philosophical thought experiments, and then answering some questions about that vignette, generally including a question about whether a concept of philosophical interest applies in this case.
There are many worries that one may have about such experimental work. In particular, one could raise doubts about the relevance of the judgments elicited, argue that such judgments (or the “intuitions” they might be taken to reflect) do not or should not play any role in philosophical analysis, or argue that while such judgments do play a role in philosophical analysis, the judgments of philosophers are to be preferred over the judgments of lay people. Alternatively, one could raise doubts about the results based on worries about the experimental approach. One might argue that the experimental context raises the spectre of experimental artifacts: that the phrasing and presentation of the materials impacts how participants respond, perhaps biasing the results.
The use of corpus analysis can help to mitigate against such potential problems, bringing to bear another channel of evidence on linguistic and conceptual claims, with the possibility of a consilience of evidence that would increase confidence in each method. The critical thing to note is that corpora by-and-large involve “real world” linguistic data—texts and utterances produced outside of any artificial experimental context. The data isn’t generated via vignettes and questions devised by an experimenter who might attempt to shape responses in a particular way, biasing responses toward the investigator’s own views. The use of corpus methods, thus, can be a valuable addition to the more common experimental methods. It can aid initial exploration and hypothesis generation and it can help confirm experimental results, testing concerns about the impact of experimental artifacts.
The use of corpus analysis in philosophy doesn’t come without its own challenges, however. Investigators should be aware of potential issues and use a range of methods to mitigate against these worries. As always, researchers should get clear on the hypotheses they are testing and the tools they are using to test. Searches will vary depending on the corpus used and what you are searching for, raising issues for interpreting frequencies and highlighting the need for relevant comparisons. Words typically have multiple forms and are used in multiple ways, which can generate challenges when it comes to testing claims about a specific sense. One could target a specific word, lemma, or lexeme depending on the corpus. A lemma is a group of all inflectional forms related to one stem that belong to the same word class. We group together forms that have the same base and differ only with respect to grammar, such as for example the singular and plural forms of the same noun, the present and past tense of the same verb, the positive and superlative form of the same adjective. A lexeme, on the other hand, is a lemma with a particular meaning attached to it, which is necessary to distinguish different senses of polysemous words. Distinguishing lexemes is a difficult task, but one that is often central to drawing a philosophical conclusion. Similar issues arise in using more mathematical techniques. For instance, semantic spaces will vary notably based on a large number of decisions, including the corpus used, how it is pre-processed, the algorithm employed and the settings for its variables.
This, of course, just scratches the surface: corpus linguistics is a large and complicated field. That said, even a rank amateur can begin to get some benefit from corpus methods today. Every philosopher can begin to integrate a simple exploration on COCA, for example, when questions about the ordinary language or concepts arise. And expertise builds over time.
* * * * * * * * * * * *
Commentary: Using Words
Colin Allen
_________
Compared to scholars in other humanities disciplines, philosophers have been slow to take up the methods of computational corpus analysis, preferring to rely on their own linguistic intuitions about meaning and use. Joe Ulatowski, Dan Weijers, and Justin Sytsma (whom I’ll refer to as “JDJ”) call this situation “(decidedly) unfortunate.” They suggest that exploration of freely available corpora can serve various purposes for philosophers, from getting a “feel” for the use of a term, to testing specific hypotheses.
I agree that philosophers can do more and (some of them, at least) should do more in this space. There are already signs of growing interest, including the work by JDJ and others whom they cite. But there are some unique challenges facing those who would incorporate such methods into philosophical research.
Let’s begin with a corpus that JDJ focus on in their piece: COCA, the Corpus of Contemporary American English. As its name suggests, it’s already a bit parochial by being focused on American usage. To be fair, COCA’s host site offers some non-American corpora too, so it is possible to broaden one’s horizons, albeit within the Anglophone sphere. There are, of course, corpora available in other languages too (e.g., DeReKo for German, and the Chinese Text Project for Chinese classics and their English translations). Multilingual corpus work presents especially difficult technical and interpretive challenges whose resolution would indeed help deepen philosophical understanding of issues lying at the intersection of language and thought. The CLICS database of Cross-Linguistic Colexifications is a potentially useful resource for philosophers, listing concepts that are lexically distinguished in some languages but not in others; for example, the different meanings of ‘savoir’ and ‘connaitre’ in French that are colexified as ‘know’ in English. (Even though this example is Western European in origin, the CLICS database has global scope.)
Given a well-curated corpus with a friendly user interface, it’s natural for enthusiasm to overcome caution. Look at how <insert favorite term here!> goes up and down over time in Google’s ngrams viewer!! See how few occurrences there are in COCA of the bigram “moral responsibility” (69) compared to “responsibility” alone (9,501) — once you exclude those pesky academic sources! Maybe it’s unfair of me to judge JDJ for the latter example, but let’s dig a bit further into their implication that this finding calls into question Matthew Talbert’s claim that “in everyday speech, one often hears references to people’s ‘moral responsibility’.” As a cyclist, I often see motorists blatantly run stop signs. No doubt many motorists have an even worse impression of how often cyclists run stop signs. Both groups run stop signs quite often — too often, we might say — and given how many stop signs there are in the city, it is a nearly everyday occurrence to see a motorist run one even if the incidence rate is below 1%.
To explore further, I recreated the COCA search using a wildcard character (*) to find all bigrams with ‘responsibility’ as the second term (see Figure 1). Notice that “moral responsibility” is number 24 on this list, with almost all of the entries above it involving function words such as “the”, “a”, “of”, “that”. Indeed among the pairs with meaningful adjectives in the first position we find that only “personal responsibility” (236 occurrences) and “fiscal responsibility” (111) are more frequent. Since COCA’s non-academic sources include newspapers, it’s not terribly surprising that these phrases should appear a bit more frequently than “moral responsibility.” What’s more, on various discourse theories, adjectives serve a disambiguating role; if the context already clearly establishes that the topic is morality or ethics, then the adjective “moral” can be dropped. At risk of sounding an even more critical note (not just judge, but jury too?!), I think that Talbert’s phrase “one often hears references” need not indicate the exact use of the phrase “moral responsibility.” In many contexts we hear references to moral responsibility even though the “moral” qualifier is implicit, or provided outside the bigram. Many of the phrases in Figure 1 such as “take responsibility” could thus involve reference to a person’s moral responsibility.
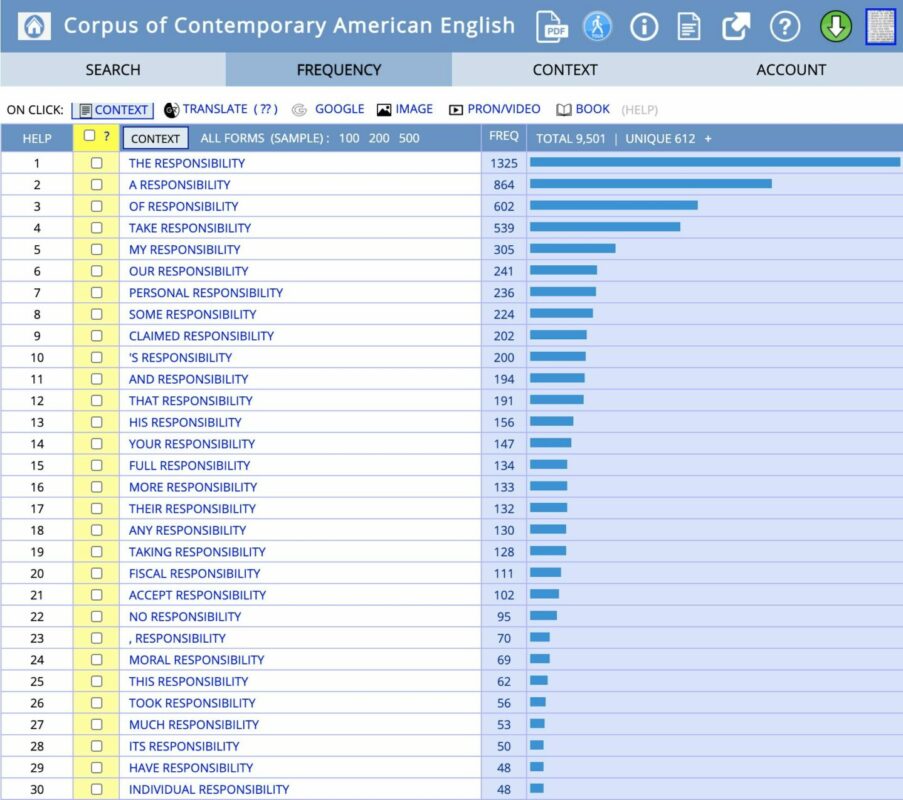
If the jury returns ‘not proven’, this is certainly no call for an executioner. Far from it: I recommend that philosophers play with corpus interfaces that have been built by researchers from other fields to figure out what might be done with them. But I also would emphasize that these word counting methods run a risk of oversimplifying the linguistic phenomena that philosophers have been gesturing towards using their linguistic intuitions. At the current stage of investigation, these intuitions are needed as a validity check. The report by JDJ about the proximity of ‘cause’ and ‘responsible’ in a simple LSA model space may hold for the specific corpus used to construct the space, but when the Google ngrams frequencies for “moral responsibility” and “causal responsibility” are compared in the much larger Google books corpus, the results are as shown in Figure 2. “Moral responsibility” wins going away, as they say in horse racing.

What to make of this is up for discussion, of course, subject to the caveats I’ve raised about matching exact phrases, context of use, and so forth. But the bigger point is that systematic use of corpus methods is going to require more than can be casually retrieved from a few publicly available corpora, as it would be overly simplistic to think that we can test hypotheses about meaning or conceptual relationships directly with such tools. It’s going to require philosophers who are willing to become more engaged in the fundamentals of corpus curation and the design of tools that are appropriate for our own purposes. Those purposes in turn will need to be fashioned to the hypotheses that philosophers care about. Coming up with better models yielding testable hypotheses is hard, creative work, resting for the time being on human-level understanding of the language(s) we inhabit. The appropriateness of corpus analysis as evidence will require a more general defense of the relevance of use to meaning, and plunges us deep into the heart of philosophical debates about how words serve as proxies for concepts.
Acknowledgements
Thanks to Jaimie Murdock for comments and suggestions.
* * * * * * * * * * * *
References
_________
Alfano, M. and M. Cheong (2019). “Examining Moral Emotions in Nietzsche with the Semantic Web Exploration Tool: Nietzsche.” Journal of Nietzsche Studies, 50(1): 1-10.
Allen, C. and J. Murdock (forthcoming). “LDA Topic Modeling: Contexts for the History & Philosophy of Science.” http://philsci-archive.pitt.edu/17261/
Andow, J. (2015). “How ‘Intuition’ Exploded.” Metaphilosophy, 46(2):189–212.
Biber, D., S. Conrad, and R. Reppen (1998). Corpus linguistics: Investigating language structure and use. Cambridge: Cambridge University Press.
Bluhm, R. (2016). “Corpus Analysis in Philosophy.” In Evidence, Experiment, and Argument in Linguistics and the Philosophy of Language, edited by Martin Hinton, 91–109. New York: Peter Lang.
Caton, J. (2020). “Using Linguistic Corpora as a Philosophical Tool.” Metaphilosophy, 51(1): 51-70.
Fischer, E. and J. Sytsma (ms). “Zombie Intuitions.” Presentation available at: https://www.axphi.org/corpus-week
Günther, F., C. Dudschig, and B. Kaup (2015). “LSAfun: An R package for computations based on Latent Semantic Analysis.” Behavior Research Methods, 47: 930–944.
Knobe, J., and J. Prinz (2008). “Intuitions about consciousness: Experimental studies.” Phenomenology and the Cognitive Sciences, 7: 67–85.
Li, Y., T. Engelthaler, C. Siew, and T. Hills (2019). “The Macroscope: A tool for examining the historical structure of language.” Behavior Research Methods, 51: 1864-1877.
Malaterre, C., J. Chartier, and D. Pulizzotto (2019). “What is this thing called Philosophy of Science? A computational topic-modeling perspective, 1934-2015.” HOPOS, 9: 215-249.
McCarthy, M. and A. O’Keeffe (2010). The Routledge handbook of corpus linguistics. London: Routledge.
McEnery, T. and A. Wilson (2001). Corpus Linguistics. Edinburgh: Edinburgh University Press.
Mejía-Ramos, J., L. Alcock, K. Lew, P. Rago, C. Sangwin, and M. Inglis (2019). “Using Corpus Linguistics to Investigate Mathematical Explanation.” In E. Fischer and M. Curtis (Eds.), Methodological Advances in Experimental Philosophy, Bloomsbury, 239-264.
Mizrahi, M. (forthcoming). “Conceptions of scientific progress in scientific practice: An empirical study.” Synthese.
Murdock, J., C. Allen, and S. DeDeo (2017). “Exploration and Exploitation of Victorian Science in Darwin’s Reading Notebooks.” Cognition, 159: 117-126.
Reuter, K. (2011). “Distinguishing the appearance from the reality of pain.” Journal of Consciousness Studies, 18(9-10): 94-109.
Sytsma, J. (ms). “Crossed Wires: Blaming Artifacts for Bad Outcomes.” http://philsci-archive.pitt.edu/18293/
Sytsma, J. (2017). “Two Origin Stories for Experimental Philosophy.” teorema, 36(3): 23-43.
Sytsma, J. and J. Livengood (2015). The Theory and Practice of Experimental Philosophy. Broadview Press.
Sytsma, J., R. Bluhm, P. Willemsen, and K. Reuter (2019). “Causal Attributions and Corpus Analysis.” In E. Fischer and M. Curtis (Eds.), Methodological Advances in Experimental Philosophy, Bloomsbury, 209-238.
Sytsma, J. and K. Reuter (2017). “Experimental Philosophy of Pain.” Journal of Indian Council of Philosophical Research, 34(3): 611-628.
Talbert, M. (2019). “Moral Responsibility.” Stanford Encyclopedia of Philosophy.
Ulatowski, J. (ms). “Does Truth Evolve? Diachronic Analysis from 1850 to 2010”
Weatherson, B. (2020). A History of Philosophy Journals, Volume 1: Evidence from Topic Modeling, 1876-2013. http://www-personal.umich.edu/~weath/lda/
We want to thank Colin for his commentary! We’re in agreement concerning the potential value of corpus methods to philosophy; and, of course, we also recognize that there are potential pitfalls. Every method can be applied with more or less care and more or less appropriately. Our goal here was to highlight the potential value of these methods, however, and we hope the potential pitfalls won’t scare philosophers off from utilizing them.
We think Colin’s critique of the examples we sketched is misguided and believe he misunderstood what those papers were actually aiming to test. We don’t want to belabor this point, however. Our goal in this post wasn’t to focus on specific examples but to discuss the general relevance of corpus methods to philosophy. And on this score, we would love to hear more from Colin and others with experience using corpus analysis concerning how they have incorporated corpus methods into their work and how they think philosophers should go about employing these tools.
-JDJ
I like the general idea behind the analysis, but I am having trouble discerning what exactly it can be useful for?
What do these corpus methods tell us exactly ?
Hi Lance,
Those not yet familiar enough with corpus linguistics to understand and comment on this post can find out about corpus linguistics and statistical analyses of corpora in the books below:
Statistics in Corpus Linguistics: A Practical Guide
Practical Corpus Linguistics: An Introduction to Corpus-Based Language Analysis
And even a cursory search on Google Scholar produces a nearly endless supply of computational corpus linguistics research.
Also, most major research institutions offer courses on the topic.
We wish you well!
Thank you Joe, Dan, and Justin, for your entry. As a corpus analysis enthusiast, I share almost everything you said.
I wonder what more can be done to get philosophers interested in these methods? I do think that corpus analysis is on the rise. At the same time, my impression is that there is still a (perhaps tacit) reluctance among philosophers to use these methods (maybe survey-style X-Phi had a similar slow start, I am not able to judge).
Here are a few possible reasons, and I would love to hear what you think?
Is it more difficult to translate ideas into hypotheses for corpus analysis than for traditional surveys?
Do we need more user-friendly tools like COCA? (We can hardly expect philosophers to learn R, or can we?)
Is there a widespread anti-Wittgensteinian attitude that also effects people’s skepticism about corpus analysis?
Are philosophers too skeptical about what use can tell us about meaning?
Does the expertise objection have a greater plausibility when it comes to corpus analysis?
One small comment about Colin’s comment. I believe the n-gram on moral responsibility and causal responsibility might only reveal that an even dimmer picture holds for causal responsibility.
Thanks Kevin! Yeah, really good questions. I’ll be really interested to hear what others think here.
I’m inclined to think that a good part of the lack of engagement is just unfamiliarity. I slowly started picking up some of these methods after seeing you and Roland present on them in Berlin several years back. (Thanks!) What especially worked for me was getting the sense that there were some easy things I could do here that would be helpful at least for exploration. Often that first step is the most difficult. Coupled with that, I think that philosophers (and others) tend to be somewhat conservative. We tend to keep doing what we’ve been doing.
Probably not surprising that corpus methods seem to be getting used most frequently now by philosophers of science and experimental philosophers; two groups that are used to thinking in terms of laying out and testing empirical hypotheses. Even so, I find that using corpus methods requires thinking about hypotheses somewhat differently than I ordinarily would in designing an experiment… and those little twists of the mind can be difficult.
Hi Kevin,
I am eager to hear from researchers who may be reluctant to incorporate corpus analysis into their own research to see if any of the possible reasons you mention track their views.
Let me speak to three of the reasons.
1) It is more difficult to translate ideas into hypotheses for corpus analysis than for traditional surveys. I’m not convinced that constructing a hypothesis is as difficult, but I do think that the methods of analysis one employs in testing corpora is distinct from traditional methods of survey use. For example, corpora are very good at testing the frequency, distribution, and dispersion of words in a corpus, and it’s good for determining the collocations of words, cross-associations, keywords, etc. Some corpora are good for diachronic analyses of change over time of a word like “true” or “truth” in comparison with other nearby words like “accurate” or “truthfulness.” Still, we need to bear in mind some limitations of corpus analysis.
Here’s one example that’s been bothering me because it shows the limitations of corpus analysis. If we set out to determine whether the word ‘intuition’ is used by philosophers as frequently now as it was in the late 19C, then someone may just run comparative tests using JSTOR data for Mind, Phil Review, J Speculative Phil, etc in “philosophy.” They may even produce an analysis that respects the difference between, say, Kantian intuitions and intuitions as immediate and unreflective responses to questions and/or examples. Of course, we should applaud such an effort, but it seemingly fails to factor in that the JSTOR category “philosophy” is an artifact of our late 20C specialisations. Philosophy and Psychology were not nearly as distinct subjects then as they are now, so a more thorough analysis would have to include journals in the “psychology” category, e.g., American J Psychology, where there were several empirical studies performed on “philosophical intuitions” under the heading “the psychology of philosophy.” This may or may not have an effect on the analysis’ outcome, but we won’t know until we test it.
2) We need more user-friendly tools like COCA and can’t expect philosophers to learn R. It would definitely be advantageous for more user-friendly tools to be developed and available for consumption! So I can’t knock that recommendation. Still, I don’t believe it is impossible to learn R, and I hope that R’s sophistication acts as a disincentive for work in corpus analysis. If you’re interested in a crash course introduction on R, then I urge you to check out Justin Sytsma and Jonathan Livengood’s The Theory and Practice of Experimental Philosophy. Chapter 10 is a helpful introduction to R for someone with no background with any computer programming language.
Here’s a second recommendation that may not be very popular. If one wants to do corpus analysis, why not ask to collaborate with people who have experience with R?
3) Philosophers are too sceptical of what use can tell us about meaning. This issue merits its own discussion, I think! It’d be great to hear from Nat Hansen whose work on ordinary language philosophy and corpus analysis of terms like “knowledge” is very informative about how to deal with such questions as whether knowledge-talk can tell us something about meaning.
Hi Joe, Dan and Justin,
Such an awesome introduction to these methods! I am completely sold on your approach as a whole, and I just wanted to ask a quick question about one of the specific case studies you use to illustrate it.
In this post, you mention your research showing that the word “cause” is usually used with bad outcomes and that it is close to the word “responsible.” (I assume you are using cosine similarity or something like that.)
I was just curious whether these are facts only arise for sentences where the cause is an agent or whether they arise for the word more generally. Consider the difference between sentences like “Joe caused…” and sentences like “The change in temperature caused…” Is your finding about bad outcomes something specific to sentences where the cause is an agent, or does it arise generally for sentences that use this word?
Thanks Josh!
Good question. The DSM results don’t distinguish between these. I think this would take some hand coding that wouldn’t be feasible for a full corpus. (At least, on a first pass I’m not coming up with a simple way to automate tagging instances involving agents vs non-agents for this purpose. Perhaps someone here will have ideas on this?) In the paper we do suggest that there is some reason to think that cause-language is used with regard to non-agents more frequently than responsibility-language, but this needs some follow-up. And we didn’t look at whether the tendency to disproportionately use this language for bad outcomes holds equally of agents and non-agents.
I did start to do some coding for a sample of sentences involving “responsible for” to sort with regard to agent/non-agent. And one thing I found is that this gets complicated. As I recall, perhaps most often the language is used with regard to group agents or what they’ve produced (e.g., “congress,” “the court,” or “the regulations,” “the law”). And then there are instances where the status of the entity is less clear (e.g., “the virus is responsible for X deaths yesterday”).
Kevin did the primary work on the non-DSM results for this paper. If he’s still around, maybe he’ll have a better sense of how things divided out between agents and non-agents?
This is fascinating! Some examples in this Stubbs paper (http://www.cantab.net/users/michael.stubbs/articles/stubbs-1995-cause-trouble.pdf) suggest that the phenomenon might extend more broadly (the medical examples; the environmental examples).
Thanks Kevin!
Perhaps worth noting that at least some dictionary definitions also pick this up (e.g., Lexico.com, verb = “Make (something especially something bad) happen.”)
Hi Kevin,
Very cool. I wish we had come across this article before we started our own research on this.
What a cool conclusion too: “These facts about CAUSE may now seem obvious. They certainly now seem “normal” to me: though they didn’t before I did this small corpus study. In retrospect, statistics often seem merely to confirm what is blindingly obvious.”
Hi Kevin,
Wow! I totally didn’t know about that. It’s definitely super helpful, and does a lot to help address my question.
In their original study, Justin et al. show that the word “cause” tends to be used with negative outcomes in a way that isn’t found for other, seemingly similar verbs (“lead to,” “generate,” etc.). The thing I was wondering was whether this effect still emerges if one excludes all of the sentences in which the cause is an agent.
Obviously, the paper you link to here doesn’t directly answer that question, but you are totally right to say that it is super suggestive and very relevant. Your point about the medical cases and the environmental cases is right on target.
Thanks!
Hi Josh
I think the short answer is “quite likely yes”, but I do not have hard evidence for this. Looking through the COCA results for “caused the death” around 40% seem to be uses in which the cause is not an animate agent (although some of these uses could be argued to be somewhat agentive in character like “the cyclone caused the death”, “the disease caused the death”.)
There are some animacy detection algorithms that one can use to filter uses with animate objects, though not in COCA. We haven’t done this so far though, but hope to do so in the future.
Also noteworthy is that “responsible for the” seems to be primarily used when an agent is the cause. So, the strong connection with bad outcomes likely holds for non-agentive causes, but the semantic similarily with “responsible for the” might not hold that strongly.
Hi Justin and Kevin,
A huge thank you for all of these incredibly informative responses. This definitely does a lot to address my original question.
I’m not sure if this will be helpful, but it seems like there might be an interesting relation between what you find here for a “cause” and a seemingly parallel phenomenon that arises for expressions like “intentionally” and “on purpose.” It seems that these expressions, too, are almost always used for bad things. For example, if someone asks you whether or not a certain behavior was performed “intentionally,” it will almost always turn out that the behavior was a bad one. I wonder whether there might be any connection between this aspect of the use of “intentionally” and your results for “cause.”
In any case, this is a wonderful example of the power of corpus methods. Given the hypothesis you are trying to test, it wouldn’t have made sense to, e.g., run an experiment in which you randomly assigned participants to get either a good or bad outcome and ask them about the cause of that outcome. The very nature of the hypothesis itself seems to call for corpus methods.
Thank you for sharing this exciting post!
I’m not familiar with this field of philosophy which seems to be quite new, though I did have heard of it. However, for me as s psycholinguist, I think using corpus to discuss some philosophical topics looks quite intriguing. So here’s some questions:
Compared to (psycho)linguists who often scrutinize very specific linguistic phenomenon, my impression on the phenomena that philosophers usually discuss might have broad coverage about human/animal cognition or knowledge (or maybe ‘meaning’). What I’m being curious about is, to what extent can the corpus analysis give the power of explanation to the theories in philosophy? Or are there any previous research with corpus analysis that nicely explained some controversial topics in philosophy?
Sorry for being ignorant in advance if my questions are too broad to answer, but if you don’t mind, I’d love to hear some comments from you Joe, Dan, Just and Colin!
Hi Kihyo,
Thanks for your interesting questions. Before trying to answer at least one, let me say that psycholinguistics could often hold important insights for philosophical uses of corpus analysis (alongside other uses). The better we understand various aspects of language use, the more likely we are to be able to use copora wisely for our investigations.
Now, regarding the use of corpora for powering explanations in philosophy… One of the ways to compare philosophical theories of particular concepts is to assess which theory most closely resembles the core aspects of how regular understand the concept. Asking regular folk for a detailed definition of a philosophically important concept is not always very successful using direct approaches, so documented use of a concept can be a reasonable proxy for understanding of the meaning of that concept. So, if two rival theories of causation were both internally consistent and were both relatively counter-example free, then more closely resembling the folk understanding of causation may be a reason to prefer that theory (especially for the more practically minded).
How the folk and philosophers understand the meaning of words in specific contexts can also have a big impact on the intuitions they might form about the cases we concoct for our thought experiments. (Thought experiments can form the basis for decisive rejections of theories in philosophy). Whether “cause” carries negative connotations may be important for a thought experiment about an agent’s moral character. If the agent in question is causing something irrelevant or morally neutral in the case, then the thought experiment might be a poor gauge of what is really at stake. Corpus analysis might be used as one source of evidence about whether the word cause usually has negative connotations, which might be able to support a more specific (e.g., survey) experiment that supports the idea that “cause” has negative connotations in the original thought experiment.
Relatedly, some of Justin’s work (with colleagues) on causation seems to get at these things, especially when considered together:
Sytsma, J. (ms). “Crossed Wires: Blaming Artifacts for Bad Outcomes.” http://philsci-archive.pitt.edu/18293/
Sytsma, J., R. Bluhm, P. Willemsen, and K. Reuter (2019). “Causal Attributions and Corpus Analysis.” In E. Fischer and M. Curtis (Eds.), Methodological Advances in Experimental Philosophy, Bloomsbury, 209-238.