My first post in this series observed that (if usage is any guide) adults attribute knowledge an awful lot. My most recent post hinted that knowledge attribution might be a necessary bridge to reach belief attribution in the course of children’s development, and ended by raising the puzzle of why knowledge attribution doesn’t fade out when we cross over that bridge. Given the general power of belief-desire explanations, why do mature adults with the concepts of belief and truth also keep engaging in heavy knowledge attribution?
The problem is made more vivid if we look at models of how we learn, from perceptible cues, which mental states to attribute to the agents we encounter. You can think of this as a computational problem, a search for some higher-order generalization behind the surface properties of outward behavior. A good model of human learning should go through the key stages we see in humans, for example switching from failing the unexpected transfer task to passing it. In the world of modelling, this is known as the shift from omniscient to representational attribution (which gets on my nerves, slightly, because positing omniscience is also positing a form of representation). Anyway, agents are at first taken as omniscient (always expected to reach for the ball in the right place, even if it had moved to a new hiding spot while their backs were turned). As learning progresses, agents start to be seen as representing the ball as being at its last witnessed location, reaching incorrectly, acting on the basis of the false belief that it is still there. As a later transition, we come to predict not only patterns of behavior where someone (who may have a false belief) wants to get something, but also patterns in which someone (who may have a false belief) wants to avoid something.
Some models don’t have much explanatory power in accounting for these kinds of developments because they effectively stipulate shifts in the rules applied by the developing learner. A more interesting type of model is capable of showing autonomous learning: working with developmentalist Kristine Onishi, Vincent Berthiaume and Thomas Shultz at McGill University have produced a constructivist connectionist model that gradually learns to predict reaching behavior, first coming to expect the reacher to be omniscient, and then later coming to view the reacher as thinking representationally. Still later their network becomes able to anticipate avoidance behavior as well.
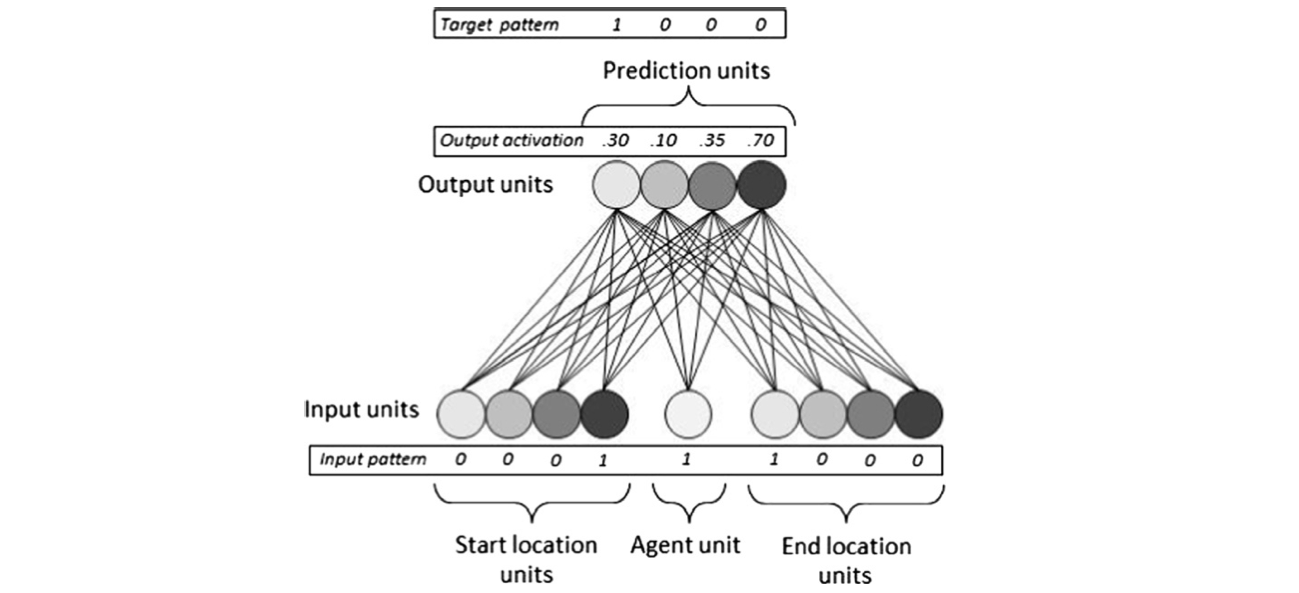
The McGill network is trained on a version of the unexpected transfer task: inputs represent the initial and final positions of an object (in an array of four positions, given color names for vividness), plus an agent input unit which represents whether the agent is or is not watching the shift. In a training phase the network is given “reaching behavior” roughly fitting the input, and in the test phase it needs to anticipate the reaching behavior to be expected in the new situations of watched and unwatched transfers it is given. One of the many things that makes this model interesting is that the input is (as in real life!) somewhat dicey. It is true that reaching behavior is generally more accurate when a shift has been witnessed, but mistakes are sometimes made in both directions (modelling forgetting/distraction and luck). The network can’t simply memorize patterns in a brute force manner (for example, deterministically plotting that whenever the object starts in the green place, shifts to yellow, and is watched, the agent must reach in yellow).
How well the network learns depends of course on the mathematical assumptions that are made in structuring the input, as well as on the computational resources the network is allowed to exercise. Under certain assumptions (most notably, too many unwatched transfers) the network won’t learn anything at all: there will be no meaningful correlations between the input and the reaching behavior that the system must predict. It’s fortunately more realistic to assume that most reaching behavior is intelligent and successful, and when it is trained on a suitably high ratio of ‘watched’ transfers (which are stipulated to produce largely correct reaching), the network does indeed start to predict reaching behavior somewhat successfully. The first real advance involves essentially disregarding that agent input node which indicates whether the shift was witnessed, and simply predicting successful search every time (“omniscience”). The McGill network can’t get beyond that stage unless it is allowed to recruit a hidden unit: in fact, the authors argue that just working with input and output units (and no hidden units) won’t enable modelling of the success of false belief predictions because their false belief task is structurally like the exclusive-or (XOR) task, which is a famously non-linearly separable problem. They argue that this result militates against accounts of false belief anticipation in terms of bare associations between agents, objects and places. Make of that what you will.
Anyway, once the hidden unit is recruited, the system has the subtlety to anticipate search at the correct spot for watching agents, and at the last witnessed spot for agents who weren’t watching a shift: it can pass the positive reaching version of the false belief task. (The avoidance task takes longer to learn, the authors argue, because a greater variety of behaviors are shown when an agent wants to avoid a target than when s/he wants to capture it.)
This particular model isn’t designed to answer certain key questions. Most notably, it doesn’t model the onset of knowledge attribution, because agent ‘watching’ is built into the system as a raw input. The model effectively assumes that belief recognition is built on a foundation of knowledge recognition: what the network learns later is that an agent’s beliefs about an object’s location will match the last known (or watched) position of the object. Earlier, at the “omniscient” stage, it seems the network is failing to make use of all the subtle information it is being given: it is over-simplifying the situation, failing to track what is and isn’t watched earlier, assuming that agents are always going to get things right, as if they have a state of mind that can only match reality.
Oversimplifications are common enough in development: children will for example over-regularize irregular verbs (“gotted”), imposing a simpler structure on the somewhat messy input they are getting. But as the child matures they mainly leave those oversimplifications behind and pick up the more subtle adult pattern. Knowledge attribution initially looks like a sort of oversimplification, but it is one that sticks: we don’t grow out of it. I mean, we do grow out of the gross oversimplification of positing omniscience — we come to see some people as lacking knowledge in some circumstances, and then later we come to see them as having various false beliefs. But we still stick to the idea that sometimes — pretty often in fact, if usage is a guide — people are in the kind of state of mind that characterizes the omniscient stage, a state of mind which must match how things are. Not a state of mind like belief, which just happens to be true in this particular situation, and might in other situations be false, but a state of mind that only ever comes in one flavor: true.
What interests me is this: success on the unexpected transfer task means taking the observed agent to have a standing assumption that things are where they were last seen. You’ve got to predict that the dupe will reach where he initially saw the ball. That assumption is, in the cases where things get moved behind the agent’s back, shown to be false. When our standing assumption is false, we have a false belief. When the standing assumption is true, however (you leave the room for a moment, nothing moves), what naturally gets attributed isn’t just a true belief. You are most often described as still knowing where the ball is. With effort you can get yourself into a philosophical frame of mind in which no one ever knows the location of anything that they aren’t watching right now (or with more effort, you can get doubts even about things that are being immediately watched), but that’s not our default. Our default is that you know where your car is parked. (Even when that was half an hour ago, and it’s outside in the dark, and your curtains are drawn.)
Why doesn’t our mature mindreading system take the agent just to have a belief that the car is where he last watched it, a belief which is sometimes false (like in those situations in which the car has been stolen and driven away) and sometimes true (like in those situations in which the car is still where he left it)? Getting reflective, we might start to worry about our agent’s inability to distinguish those conditions in which his standing assumption is true from those in which it is false. Doesn’t that somehow undermine our agent’s claim to knowledge, on those happy days when nothing happens behind his back? If it would be more economical (and, it seems after certain types of reflection, more fitting) to think in terms of belief all the time, why are we still attributing knowledge?
My friends in epistemology will notice the allusion to the Harman-Vogel paradox here, a problem I’ve wrestled with in the past. Great Scott, this post is getting long, I’ll carry on next time, and with luck, bring us back to the Gettier problem too.